One trend continued to emerge with unsettling consistency after working with firms in the fields of logistics, healthcare, and BFSI.
Despite teams investing in automation platforms, implementing new software, and digitizing their workflows, the same barrier persisted. Compliance officers were still reconstructing audit trails from the beginning, since no one had properly structured the records the first time. Analysts were still straining at fuzzy PDFs, and finance teams were still re-entering invoice data that already existed someplace else.
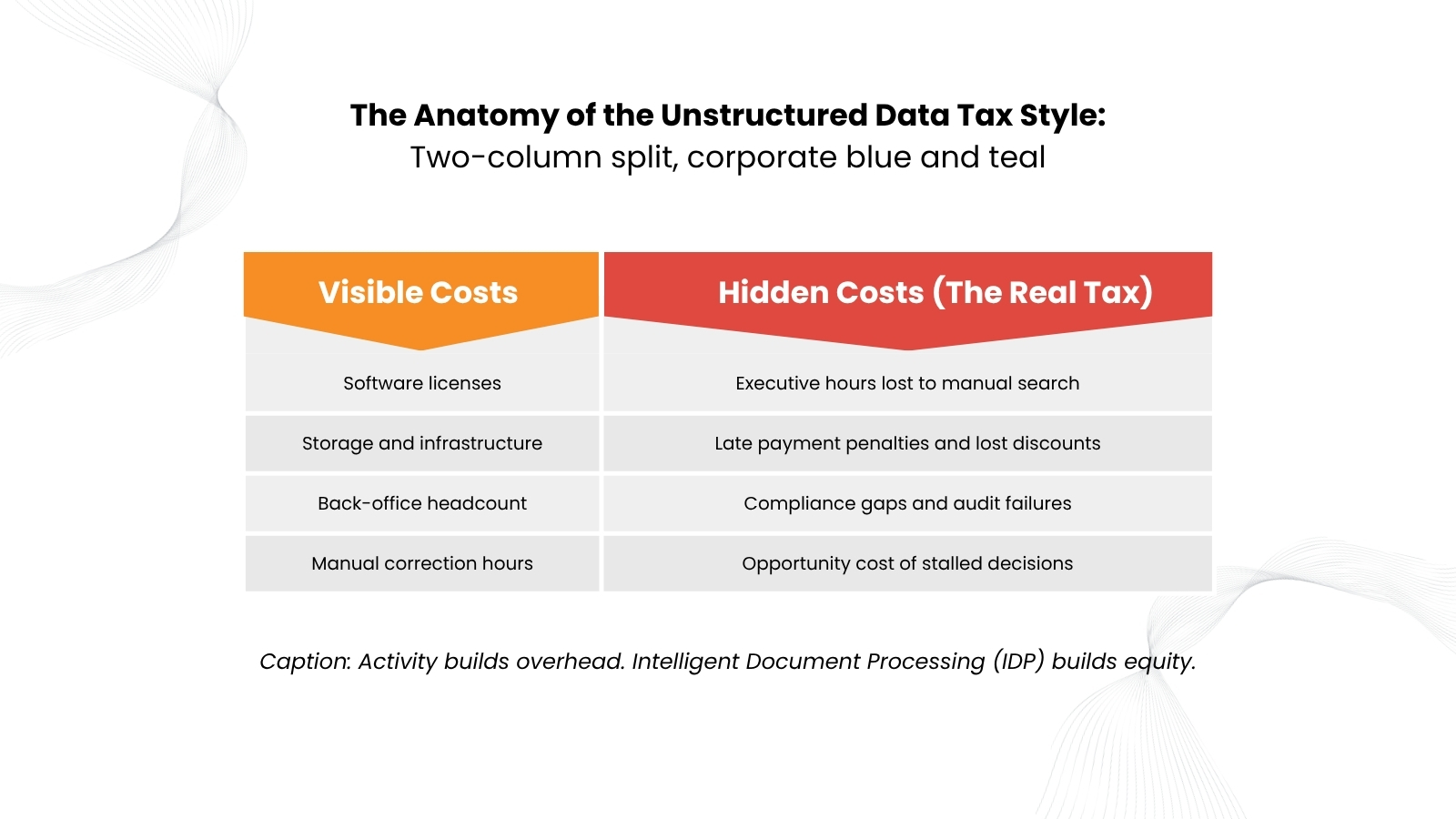
Most businesses pay this tax known as the Unstructured Data Tax without ever recognizing it.
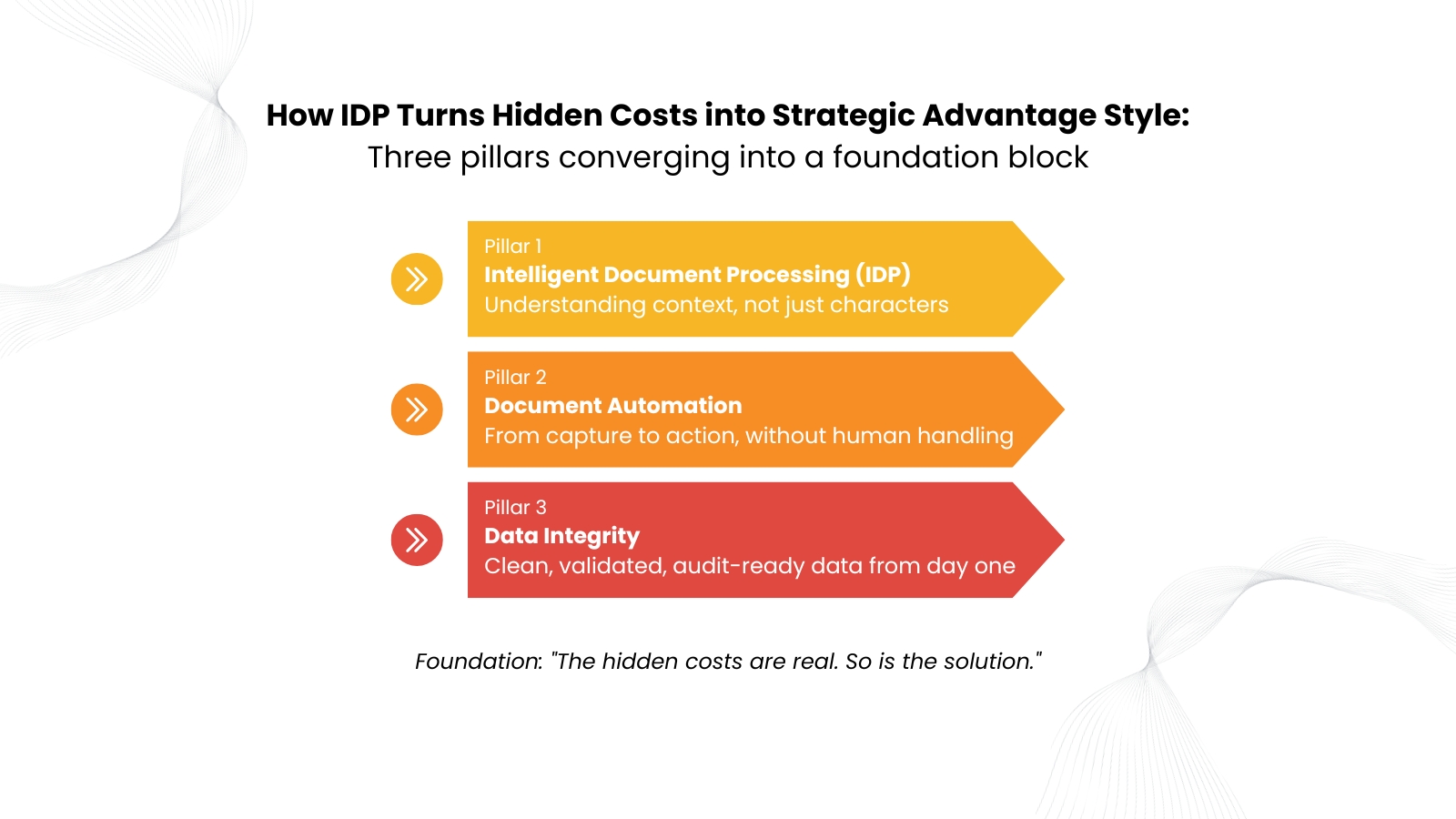
Most of the companies we’ve dealt with already have document automation solutions, so that was not the issue. Without intelligence, automation only accelerates chaos, and when chaos accelerates, hidden costs do not decrease. They simply becoming more difficult to locate.
Having a PDF is not the same as having data. If a human still needs to open that file, read it, extract a number, and type it somewhere else, that document is Dark Data, which is unstructured, unindexed, and expensive. It is a 1990s paper problem wearing a digital costume.
Most organizations respond by adding headcount or deploying legacy OCR tools, but legacy tools recognize characters, not context. The moment an invoice arrives from a new vendor in a slightly different format, it becomes an exception, exceptions pile up, and the team that was supposed to benefit from Document Automation ends up managing its failures instead.
This is the Digital Plateau, where automation stalls at 60%, the remaining 40% becomes someone’s full-time job, and leadership wonders why the ROI never arrived.